In observing the language that CIOs and CMOs alike keep using around the big data bubble — where both parties seem ready to acknowledge that marketing is in the hot seat for making productive use of data — I’m starting to conclude one of two things:
- “Data” is a euphemism for all application-level marketing technology.
- There’s an illusion that data-driven marketing can thrive independent of any deeper engagement with the technology that generates or harnesses this data.
If it’s a euphemism, I guess it’s a clever way for the marketing organization to boost its internal technical capabilities without directly challenging the IT department’s sovereignty over technology. “Yup, IT is in charge of technology, we’re just doing what we need to do here in marketing with, um, data. Just working with data. Nothing to see here.”
But I suspect that in many cases it’s an illusion that marketing and IT leaders would prefer to believe: that data and the technology for which that data is input or output can be cleanly separated.
If that were true, it would conveniently sidestep messy issues around distributed technology governance and the integration of software development talent directly into marketing’s structure and culture. We could maintain the Ptolemaic model that perfectly divides software and marketing into two different departments.
Unfortunately, it’s not true. Or more accurately, it’s only true under limited constraints.
Data may be static, but data-driven is always dynamic
It’s true if you look at data as a static, fixed asset that’s generated by some other static, fixed asset. “Here’s the data,” handed off in a spreadsheet or distilled into set of PowerPoint charts. First generation web analytics were the epitome of such data. There is value in that data, but it’s relatively low fidelity, like listening to a static-y radio station in your car with no dial to adjust the frequency. (Admittedly, that analogy is a bit anachronistic here in the age of satellite radio and Bluetooth-connected Spotify or Pandora, but you get the idea.)
But being data-driven is something else entirely. It’s not static — it’s dynamic.
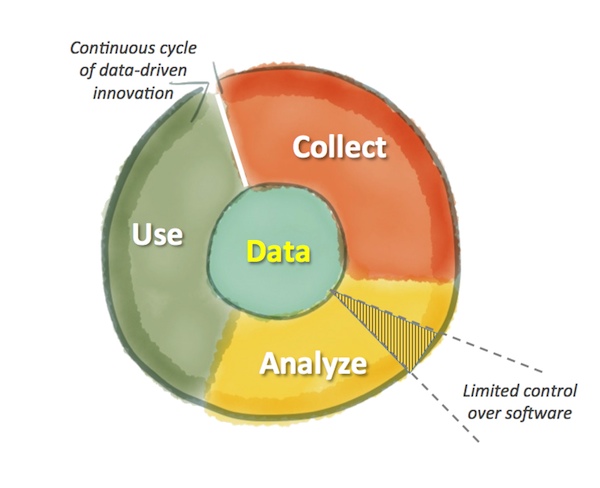
When you’re data-driven, you engage with the entire “circle of life” of data — as illustrated at the top of this post — how it’s collected, how it’s analyzed, and how it’s ultimately used to affect outcomes with customers.
If you hardwire the way in which data is collected, dictate the tools that can be used to analyze that data, and tightly restrict how the results can be operationalized in changes to the business, that circle of life withers into the desert. You don’t get a thriving data-driven ecosystem; you get an animatronic exhibit that passes as “analytics theater.”
Being data-driven is about actively exploring new ways of looking at data — which is much of the excitement around big data technologies that help find patterns across less structured data sources. Being data-driven is about turning those insights into hypotheses, and turning those hypotheses into controlled experiments. This is what I call big testing. And being data-driven is about taking those winning tests and rapidly scaling them into compelling and differentiated customer experiences (“big experience”).
In the process of doing that, however, you’re also generating new data to be collected. In fact, the purpose of many experiments is to specifically harvest new kinds of data to feed into your analysis and subsequent tests.
That is the vibrant circle of life of data in a data-driven organization.
But here’s the revelation: every stage of this circle of life of data involves configuring, tinkering, hacking, or outright developing software. Being data-driven is about fluidly adapting and improving an organization’s operations, and in a digital world, such change almost always manifests itself through changes to software.
This is why data will be marketing’s gateway drug to embracing software leadership.
Data scientists will hook up marketing with software
The first thing you must know is that data scientists are effectively specialized software programmers. Thomas Davenport and D.J. Patel, in their HBS article Data Scientists: The Sexiest Job of the 21st Century, wrote: “Data scientists’ most basic, universal skill is the ability to write code.”
In fact, a common joke at big data gatherings is that, “A data scientist is a statistician who knows more programming than any other statistician and a programmer who knows more statistics than any other programmer.” The joke is that, obviously, great data scientists are rather hard to find. But the subtext of the joke that can’t be ignored is that programming capability is an inherent part of the data scientist role.
For instance, consider the Data Science Starter Kit collection of books from O’Reilly:

All of these books — 8 out of 8 — involve programming, whether in R, Python, or Javascript. Several of them dive into fairly advanced computing concepts such as machine learning, map-reduce distributed computing, and natural language processing. And these books just deal with the “analyze” stages of data’s circle of life!
Why so much programming?
See, data scientists will not stay boxed into a fixed set of pre-canned tools. They use their coding chops in creative ways to mash and manipulate data, pull from multiple data sources, and explore new data relationships and ways to visualize them. They’re constantly pursuing new discoveries. As Davenport and Patil wrote in their article, “In a competitive landscape where challenges keep changing and data never stops flowing, data scientists help decision makers shift from ad hoc analysis to an ongoing conversation with data.”
Of course, not everyone who works with data needs to be a full-blown data scientist. However, having some true data science capability — especially in this era of big data — is a tremendous advantage to a marketing department. Through the work of a small number of data scientists, maybe just one, many others can be empowered in data-driven marketing.
But here are the two key influences that data scientists will bring to marketing’s overall software savviness:
First, having programming talent in the marketing department will organically spread “software thinking” in the organization. This will happen through day-to-day meetings and collaborations between data scientists and others on the marketing team. More and more marketers who were comfortable with Excel will be coaxed into using a little bit of code in their work because, frankly, it will give them more power in what they can do. Even those who don’t feel comfortable dipping their fingers in a code editor will see close-up how code is being applied to the marketing mission in a variety of different circumstances. They will naturally get better at talking the language of software with their compatriots.
Second, data scientists will seek to apply their programming talents to the “collect” and “use” stages of data’s circle of life. When they uncover exciting new hypotheses from their analysis, they’re going to want to test them in the real world. They’ll proactively find ways to implement new ideas in the applications that touch customers. And with their programming skills, they certainly have the technical capacity to whip up many quick experiments together themselves. In some circles, they call this “growth hacking.” All that’s needed is access to the front-facing applications, which are mostly web-based and increasingly owned or co-owned by marketing, and permission to give it a try. (Or, for more brash data scientists, simply a willingness to ask forgiveness instead of permission.)
Since the marketing executives that these data scientists report to are hungrily looking for results to show that their investments in data-powered marketing can pay off, there will be a lot of pressure from the CMO to give them that access and permission. And once the circle of life of data gets moving, cycling through new ideas with increasing velocity, there will be no turning back.
Suddenly the marketing department has software fluency.
And that will be a really good thing.


Scott,
Thanks for sharing this information and especially providing description around data scientist.
My favorite part is when touched on a reality …. “Yup, IT is in charge of technology, we’re just doing what we need to do here in marketing with, um, data. Just working with data. Nothing to see here.” Be it data or any other program that has anything to do with technology.
I have seen is at few places that the key focus of Marketing team is in conversion/leads and everything related to data falls into the big word of Big Data. At all these places I have observed that even the Marketing team thinks that they have nothing to do with data other than analytics and it should be only taken care by technology offices.
The biggest challenge I see is making the need and benefits understood by the Marketing team.
Thanks & Regards
Rohit Prabhakar
Pingback: The Top 12 Marketing Automation Articles Curated Today, Thursday, 2/14/13 « The Marketing Automation Alert