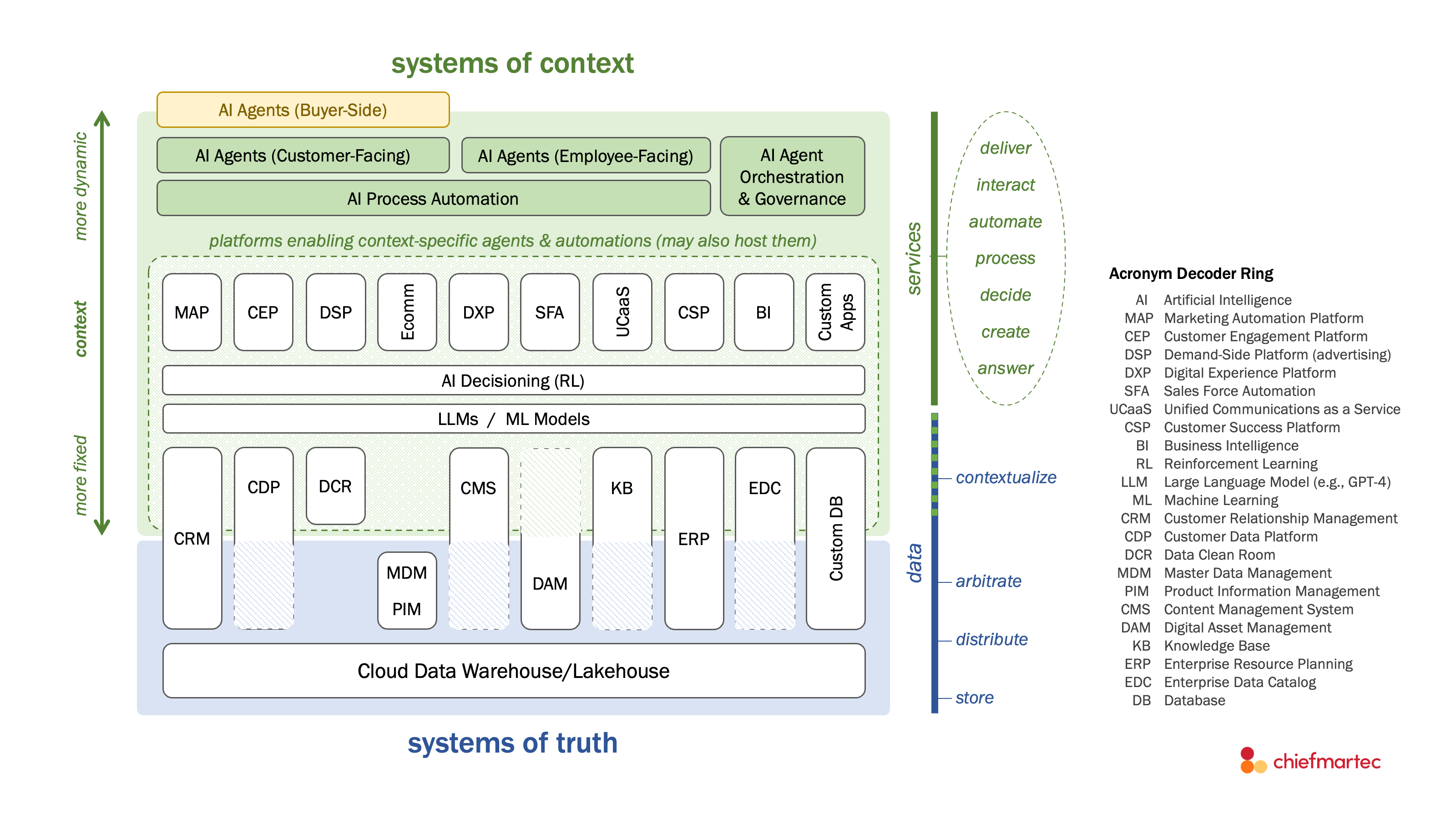
For years, martech was divided into systems of record and systems of engagement.
Systems of record stored the “master” versions of data. CRMs and CDPs for customer data. PIM for product data. DAM for brand assets. ERP for inventory data. (I know, there’s a ton of acronyms in this piece, almost to the point of parody. Click on the image above for a larger-scale version to read the Acronymn Decoder Ring on the right.)
Systems of engagement interacted with customers, either directly with tools such as MAP-delivered email or DXP-delivered web experiences or indirectly with tools such as SFA supporting sales teams who engaged with customers.
In reality though, this division wasn’t quite as clean. For instance, CRMs and CDPs often blended data management and customer engagement functionality. But as a way of talking about different martech categories and their roles in a tech stack, it sufficed.
But I don’t think it’s the right mental model anymore.
With the AI revolution sweeping everything in marketing and technology, I believe a better framing is systems of context and systems of truth.
Now, squinting at my diagram you might ask, “Isn’t this just systems of engagement and systems of record with different labels?” They’re similar, yes. Both roughly delineate a layer of data and a layer of services. But here’s why they’re different.
First, at the data layer, systems of record historically combined responsibilities for both storage and arbitration of data. Each system of record had its own database that was tightly coupled with business logic to determine what could be written to or read from that database and in what format.
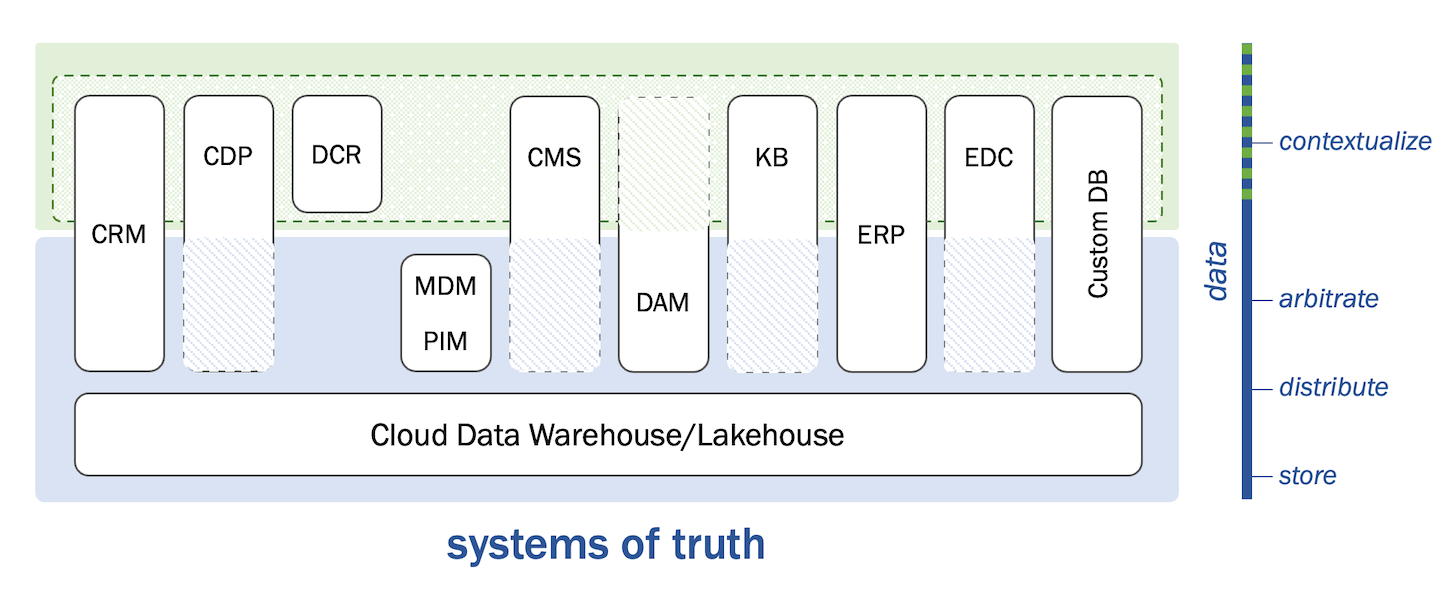
In the model I’ve sketched here, the systems of truth section of the stack acknowledges that these concerns of storage and arbitration have now been separated, thanks to the rise of the cloud data warehouse/lakehouse.
Cloud data warehouses/lakehouses store and distribute data across the organization. But the very strength of this universal data layer — that it can house any and all data flowing across the organization — is also its weakness. Data flooding through it isn’t necessarily standardized or rationalized across all its various sources and destinations. Conflict and contention can run rampant.
You still need software to arbitrate what is correct and canonical data, governing how it gets written or read, in what format, validated with standard definitions and relevant business logic. With something as important and complex as master customer records — what is traditionally stored in a CRM — such arbitration and governance is non-trivial and mission-critical.
This is why many “classic” martech systems of record — CRM, MDM, PIM, DAM, etc. — still play an important role in the cloud data warehouse/lakehouse era: they remain the arbiters of truth for data within their domain. Even if their data is increasingly stored in an independent layer further down.
Will there be a new generation of such data arbiter platforms? Or will the current leading platforms of today evolve to adapt to this new environment? Probably both.
These classic martech data platforms also provide useful contextualization of data. For instance, combining a list of customers with a set of advertising audience segments creates a context for that customer data within a specific marketing campaign. This is exemplified with composable CDPs. They work directly with the data stored in a cloud data warehouse, but they organize and manage that data for a wide variety of different contexts in which marketers want to use it.
In fact, a composable CDP is arguably more system of context than system of truth.
(If the word “truth” bothers you for philosophical reasons, and you’d prefer we change it to something else, sorry, we Kant.)
We never achieved a true single system of truth (SSOT). Turns out there are just too many domain-specific data truths. But with a universal data layer on bottom and domain-specific data governance platforms on top, we now have many systems — plural — of truth.
So what makes systems of context different from systems of engagement?
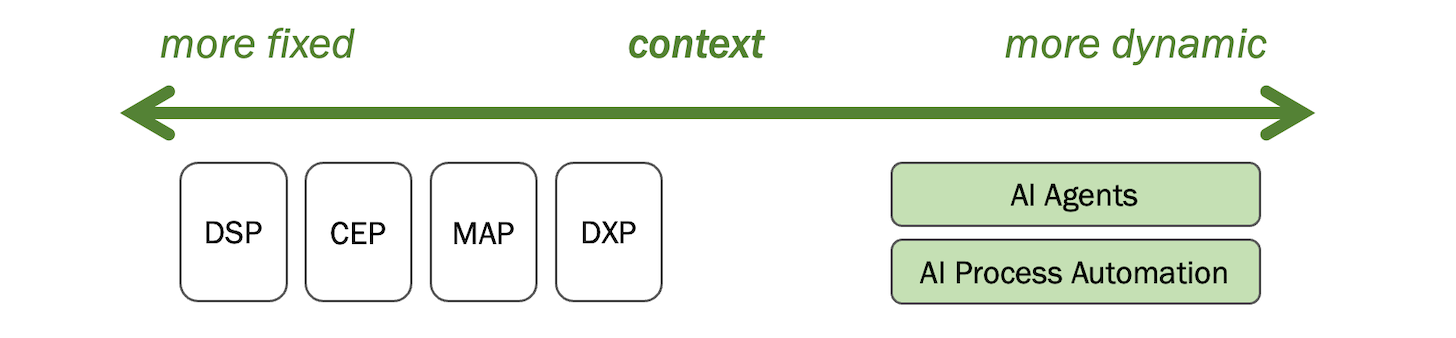
Systems of engagement have been relatively “fixed” in the context they provided. For instance, with MAP and CEP platforms, you learned how to use them, often adapting the way you work to their structures and processes. When you built a website on a DXP, the experience customers received was the context you had mind for them when you designed it. It’s not really their context. It’s the context you think they have.
With the rise of AI agents, both employee-facing and customer-facing, context is being created more dynamically. Many AI agents can be spun up, each tailored to a specific task or workflow for an employee or hyper-personalized for a specific customer’s experience.
Systems of context differ from systems of engagement quantitatively — increasingly, there are more AI agents proliferating across the stack than traditional SaaS platforms — and qualitatively because they’re purpose-fit for much more specialized contexts.
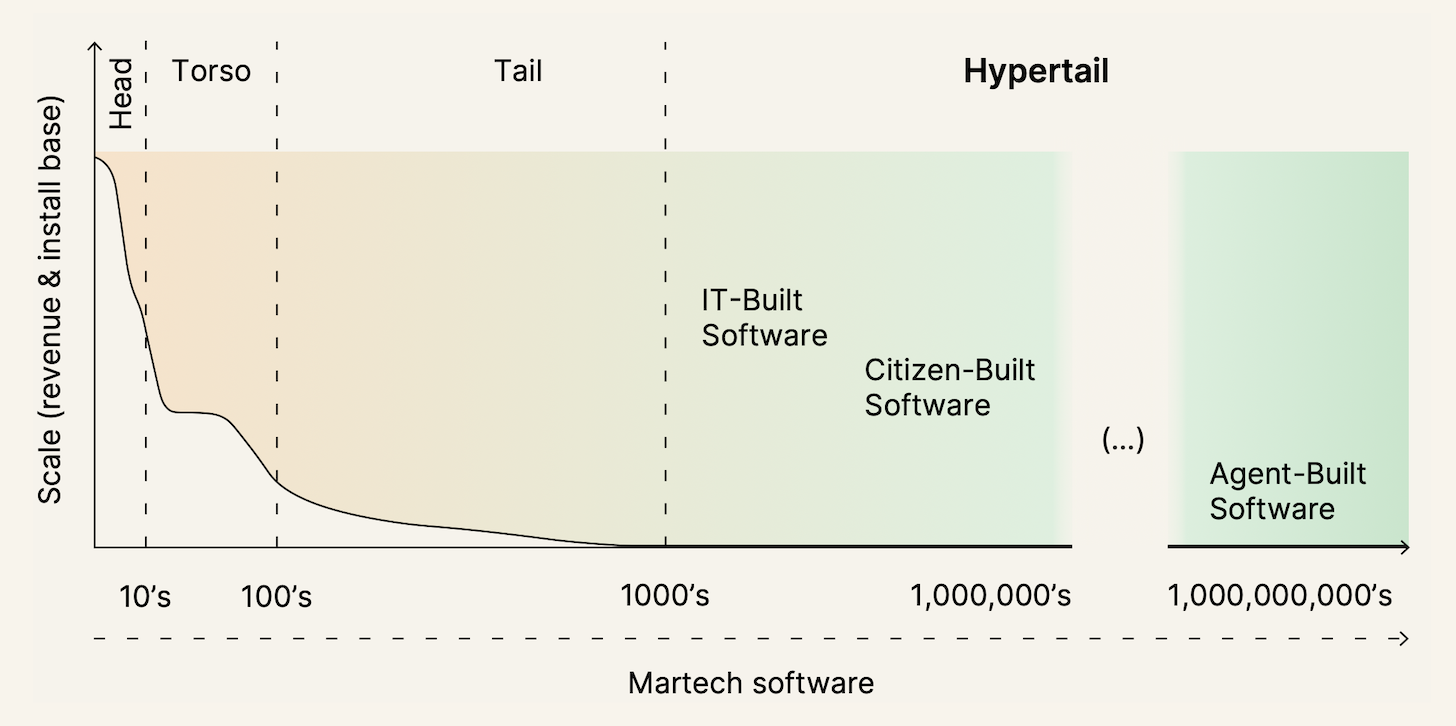
The extreme incarnation of this is individual AI agents that create software experiences on-the-fly for each employee or customer, for whatever job-to-be-done they want completed at that moment. This is what we described as the new “hypertail” of martech software — in aggregrate, billions of software apps created on-demand by AI — in our Martech for 2025 report a couple of months ago.
Dynamically-generated customer-facing AI agents, which we’ll call concierge AI agents, will deliver much more contextually relevant experiences to those users. They’ll listen to exactly what the customer wants, and informed by all existing customer and company data in our systems of truth, deliver exactly the content and services the customer wants in that exchage.
Instead of a monologue, where a brand serves a contextual experience based on its own definition of the buyer’s journey and what it thinks the buyer wants, concierge AI agents will engage buyers in a true dialogue to understand and serve their actual context.
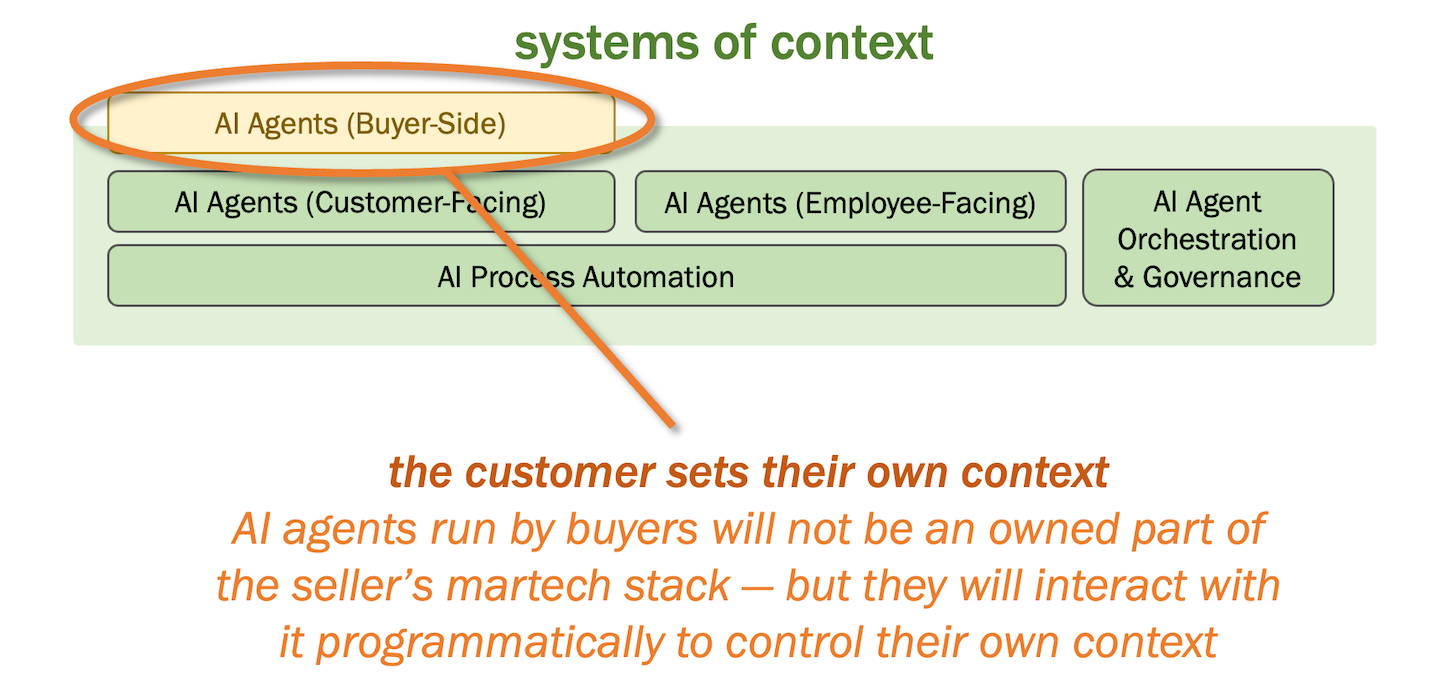
A little farther out on the horizon — but maybe not that far — buyers will use their own AI agents to interact with our systems of context. These aren’t customer-facing AI agents that sellers control. These are customer-owned AI agents that they control. They will inherently shape the experience to the context of the buyer.
Two more points:
First, in the stack schematic at the top of this post, I included a whole bunch of different martech product acronyms. I’m not saying that every stack needs all of these. Unless you are at a large enterprise, you probably only have, need, or want a subset. I only included a bunch to show where I thought these different categories fit in this architecture. It is also by no means comprehensive.
Second, illustrating this as a stack — components neatly packed together, stacked on top of each other like perfectly fitting Lego blocks — isn’t a really accurate representation of reality.

The stack view is easier to understand — at least I think so, given that’s how we’ve thought about martech stacks for so long.
But a more accurate representation would be a graph view. All of these different products and platforms, and all these different apps, agents, and automations, are all nodes in the cloud that connect with any of the others. I still think of systems of truth at the center of this cloud, surrounded by many systems of context.
In summary, yes, we still have records, and we still have engagement.
But the defining characteristic of the martech “stack” in an AI world is going to be context and the truth it’s wrapped around.
P.S. Speaking of martech stacks, we hope you’ll consider sending in a slide illustration of yours for our 2025 Stackie Awards. It’s seriously one of the most fun awards programs in all of marketing — admittedly in my highly biased opinion. But there’s no fee to enter, and in fact, we donate $100 to UNICEF for every legit entry, up to $10,000 total. Deadline to enter is April 4.

Get chiefmartec in your inbox
Join 42,000+ marketers and martech professionals who get my latest insights and analysis.