A few months ago, I read a fascinating article published by the Lyft Engineering team on Medium, Building Lyft’s Marketing Automation Platform.
While we know there are a lot of homegrown martech systems in the wild, it’s rare for them to be described publicly. I’ve referred to them as “dark martech” because of that lack of visibility across the industry. Yet like dark matter, there’s reason to believe that these custom-built apps make up a significant portion of the code running in the marketing universe.
Calling it “dark martech” isn’t meant to have a negative connotation. It’s not dark because it’s bad. It’s dark because it’s hard to see or measure outside the walls of individual companies. You know it’s there, but quantifying it is difficult.
As with the example from Lyft, these solutions often arise at the intersection of marketing and the actual operations of the business itself — entangled in the “special sauce” of delivering your overall customer experience. For instance, when you think about it, most website apps — which do something more than just deliver static content — are common examples of these custom developments.
Often, these bespoke solutions aren’t entirely bespoke. They’re built on top of or integrate with commercially available apps and platforms.
But a custom system for marketing automation isn’t something I hear as often. So I was excited that Ajay Sampat and Patrick McGrath of Lyft, who built their system, agreed to do a Q&A with me to discuss why and how they tackled this mission.
1. Earlier this summer, you published a terrific article on Medium describing how Lyft built its own marketing automation platform. I’d love to step back and first ask, why did you decide to build your own instead of adopting a commercially available solution? Functionality? Price? Control?
Managing the service levels of our marketplace through online advertising platforms is a complex challenge. Lyft services more than 400 regions across the US, and the service levels of each market — price, ETA, driver earnings — are different. As a result, the value we assign to an incremental driver or rider in each market is dependent upon the current and forecasted service levels of the marketplace.
For busy markets where ETAs are high, we assign more value to an incremental driver, as there is unmet rider demand in that market. The converse is also true — if service levels are satisfactory, adding an incremental driver is often going to be detrimental to the market, as now the same amount of rides have to be split between more drivers, leading to overall lower driver earnings.
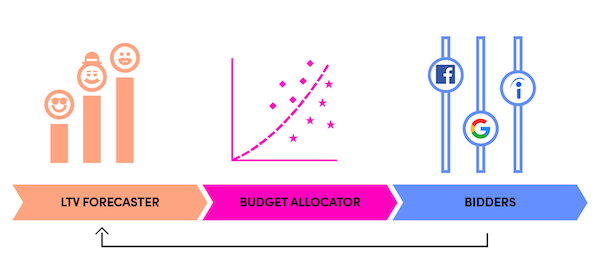
Due to the challenges of managing a marketplace, we needed our marketing automation system to be tightly coupled to core internal systems — namely, customer lifetime value prediction, attribution, and marketplace service level forecasting. We needed to know exactly how much to spend today and the implications to the marketplace 2, 8, or 16 weeks into the future.
When evaluating commercially available solutions, we came to the conclusion that:
- The most expensive components of the platform are the internal services — LTV, attribution, and forecasting.
- The actual bidding interfaces to the advertising platforms were relatively low cost.
So, because the bidding interfaces were less costly to build and maintain, and because having control over all of our data allowed us to more effectively improve the core expensive components of the platform, we decided to build this all in house.
In retrospect, this was definitely the right decision — we have made numerous improvements to the core components of the platform, which have resulted in substantial cost savings, improvements that would have been made substantially more difficult if we did not own the end-to-end data pipeline of how bids were being published.
2. The article was released on the Lyft Engineering publication on Medium. Was this an engineering project or a marketing project? Or kind of both?
“Symphony,” our marketing automation platform, was a cross-functional project between product, engineering, marketing, and science.
We had a core team of 7 engineers and 4 scientists developing the platform. A product manager and engineering manager facilitated planning and execution. We had two marketers embedded with the engineering team to provide context to technical specifications and to QA first versions of bidding components, bid outputs by the model, and to help us QA initial versions of the bidders which often made suboptimal decisions.
In terms of who funded the project, that was also a split between marketing — who we consider the customer of the platform — science, engineering, and product.
3. What was the process like for designing and implementing the platform, deciding what it should do, what its scope should be? How about after its initial release, for ongoing operations and development?
In previous automation investments at Lyft, we generally observed a 20-30% improvement to the cost efficiency of automating activities otherwise managed by humans, such as coupon spend allocation. So, our optimistic expectation of payback here was (1.3 * current marketing spend) – (current marketing spend). Publicly, this figure was about $700M in 2018, meaning the efficiency gains we were expecting were north of $150M annually.
In previous automation investments at Lyft, we generally observed a 20-30% improvement to the cost efficiency of automating activities otherwise managed by humans.
Additionally, we had been running one-off experiments testing out various scripted bidding strategies, and we knew that we could generate gains by automating pieces of the marketing pipeline.
With this evidence, and alignment across the growth org, we started from the problem we wanted to solve:
- Managing bidding and budgeting manually is time-consuming.
- We don’t know how likely our driver leads or new rider installs will lead to valuable rides.
- We don’t know how to assign credit between the various marketing touchpoints that lead to valuable rides.
- We don’t know what the market is going to look like when drivers actually go through the onboarding process and start taking their first rides (sometimes as long as a year from signing up).
Additionally, our growth strategy was to buy drivers and riders on the margin. But when the “margin” is a moving target dependent upon future service levels of the market, this means that the price we are willing to pay today for a user might be different than two weeks from now. We needed a means of moving up or down a “cost curve” of spend and volume in a predictable way.
The problem framing then lead to planning out what the core components needed to accomplish — the infrastructure plan, technical specifications of each component, API interfaces between components, and how the various models would be trained.
Once released, the “product” we built here was effectively a massive data pipeline across 30+ scheduled procedures: model training, validation, deployment, bid publishing, campaign automation, logging, repeat.
We set aggressive timelines to roll out the project and reported on progress on a monthly basis, planning monthly sprint cycles and giving the team as much heads down time to ship the product as possible. The release process was effectively a controlled rollout to our markets, with a continuous split to observe “control” — or human-managed — markets and the markets the software was actively managing the budget.
After initial release, project planning for the team consisted of impact sizing — where we thought we could generate the most gain in efficiency — relative to engineering level of effort. This allowed us to invest in things such as improvements to our LTV models, attribution models, etc.
The North Star metrics for the platform today is and always has been marketing cost efficiency, with sub-metrics such as platform reliability also being monitored and improved.
The team has only increased in size as we have started to automate things like campaign and creative creation, and have invested in better insights for our marketing teams to feed the machine winning campaign strategies.
4. While your overall solution was a bespoke marketing automation platform, did you employ or integrate with any commercial components as part of your implementation? What would be the line in deciding between whether to build or buy a particular component or service?
The entire stack is bespoke. This was made substantially easier due to having amazing internal services teams. We have an ML platform team to make training and deploying models easy and a data platform team to make managing clusters and cron jobs easy — both of which seriously cut down the requirements and scope of the project.
The decision criteria for buying commercial here is always cost-to-build vs. cost-to-buy. Strategically, we wanted to build bench strength in our org around marketing automation, so it made the build option attractive to us, even when the costs to buy a third-party solution — such as attribution-as-a-service — were very low.
Lyft is still in its nascency in understanding marketing effectiveness, and we consider the platform we’ve built as a competitive differentiator — in part due to the amount of expertise we’ve developed internally as a result.
Eventually, we will plug in best of breed commercial components, such as data management, particularly as we start to scale our programmatic marketing efforts.
Eventually, we will plug in best of breed commercial components, such as data management, particularly as we start to scale our programmatic marketing efforts. We have not crossed that bridge just yet.
5. For other companies who read this and say, “perhaps we should build our own marketing automation platform too!,” what would be the trade-offs you would suggest they consider? What capabilities does a company need to pull to this off successfully?
We get asked this question almost on a daily basis, and thankfully I can say the answer is quite straightforward:
- You will likely see a 15-30% improvement in marketing cost efficiency for any spend managed by reinforcement learning.
- Starting from scratch, the project will take 60-70 months (e.g., 8 people for 8 months) to release an initial version. If the alpha generated from the cost efficiency improvement is enough to pay for the opportunity costs of that investment, then go for it!
- You need people with strong distributed systems backgrounds and a scrappy engineering/science team that is capable of framing, communicating, and solving machine learning problems.
- Data infrastructure will be the greatest challenge: validation, anomaly detection, memory allocation, and query efficiency — all of these are costly endeavors.
Another way to think about the why of building a platform like Symphony: if you observe high variability in conversion rate, cost/user, or value/user, then a machine learning platform is a great way to capture gains by predicting and exploiting those variabilities.
I realize this is a substantial undertaking for most companies, and to that I say: the most valuable component of this entire system is the prediction of lifetime value.
Bidding platforms are making it easier and easier to send real-time predictions of value to inform bidding strategies, and if you only invest in one piece of a marketing automation suite — LTV modeling and prediction, with continuous improvement to the precision of the model — is absolutely the best bang for the buck, and has a short timeline to generating returns.
6. What advice would you give to other companies on balancing the intersection of product, marketing, and growth overall?
Start with the value you want to generate for your users. For us, it was a balanced marketplace. As a user of Lyft, we all want a great ETA at a reasonable price.
From there, work into what is preventing you from achieving that value. These discussions can happen across all functions of the organization.
When developing complex systems, the team needs to be protected from the effects of Conway’s Law.
Once a problem has been chosen to be solved and a solution has been agreed upon — and this is the most important piece of advice — let the team do the work. In particular, when developing complex systems, the team needs to be protected from the effects of Conway’s Law. Let the constraints of the solution space inform system design, not the constraints of the organization.
Set the team up with transparent success metrics and keep the status updates to a minimum. Relentlessly protect the plan and the team’s time. Great things will happen as a result. I think this statement is universally true for software development but is substantially more important when developing marketing automation software.
Thank you, Ajay and Patrick.
Intrigued enough by this that you might want to join the team at Lyft? They asked me to let people know that they are hiring and there are some great opportunities open there.
Get chiefmartec in your inbox
Join 42,000+ marketers and martech professionals who get my latest insights and analysis.