Now that major companies are implementing linked data, and more marketing thought leaders are championing data as an outward-facing competitive advantage, the question I’m hearing more frequently is:
How do you turn data into revenue?
Creating, publishing, and maintaining data takes work. What are the economic incentives for companies to put in the effort?
Here’s my take on 7 business models for data web initiatives:
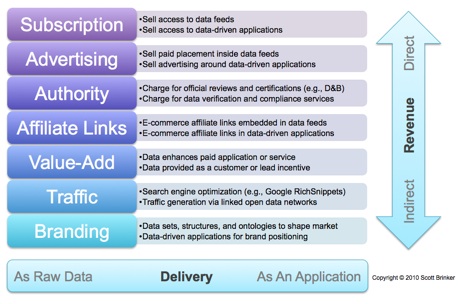
I’ve organized these by how revenue is generated, from direct money-for-data to indirect branding programs.
Within each of these revenue models, there’s also a secondary dimension of how the data is delivered, whether in raw form for others to leverage in their own applications or embedded into a pre-packaged application provided directly to end-users.
1. Subscription model. Some data will be valuable enough that you can charge people a subscription to access it. This model has been around for a while, but it will gain new life as linked data standards make it easier for people to consume and mash-up data in novel applications.
2. Advertising model. Advertising: the second oldest profession. Data-driven applications will have plenty of opportunity for contextual ads and sponsorships. One interesting twist will be advertisers who pay to include information in raw data feeds, data-layer ads if you will.
3. Authority model. If anyone can publish data on the web, how will you know what data is good? That problem will be an opportunity for third-party “authorities” to validate data — or do official reviews and certifications that are published as data — and charge for participation. Compliance services are related to this.
4. Affiliate model. Affiliate marketing programs generate over $6 billion/year in commissions and are a major source of transactions and leads for merchants such as Amazon.com. Embedding affiliate links in data, so that they are activated when surfaced into end-user applications, are a natural extension of this existing model.
5. Value-Add model. Useful data can be bundled with other services to make the overall solution more valuable. For example, think of the benchmarking data now included with Google Analytics. Access to data can also be offered earlier in the sales funnel, as a lead generation incentive.
6. Traffic model. As with Google Rich Snippets, data can be used to boost the visibility and ranking of sites in major and vertical search engines. This is data-enhanced search engine optimization (SEO++) to increase traffic. Nickname: the “data for nothing and links for free” model (apologies to Mark Knopfler).
7. Branding model. As Josh Jones-Dilworth said, “Data shapes conversations and markets.” Data branding can use data — and the vocabularies that define and structure data — to position and promote a company’s worldview and differentiation strategy.
Of course, there will be hybrid models that combine several of these approaches.
Particularly in the early days, most organizations will benefit from experimenting with linked data for traffic, branding, and a little value add. Their own value will be learning as much as anything. As the data web matures, and they become more experienced, they may embrace more direct revenue models.
But don’t underestimate the importance of data branding. When it comes to establishing industry standard vocabularies and ontologies, there is a definite first-mover advantage.
For the entrepreneurs in this space, however, everything is fair game.
Can you think of other models? Are you willing to share?
Get chiefmartec in your inbox
Join 42,000+ marketers and martech professionals who get my latest insights and analysis.