Now that major companies are implementing linked data, and more marketing thought leaders are championing data as an outward-facing competitive advantage, the question I’m hearing more frequently is:
How do you turn data into revenue?
Creating, publishing, and maintaining data takes work. What are the economic incentives for companies to put in the effort?
Here’s my take on 7 business models for data web initiatives:
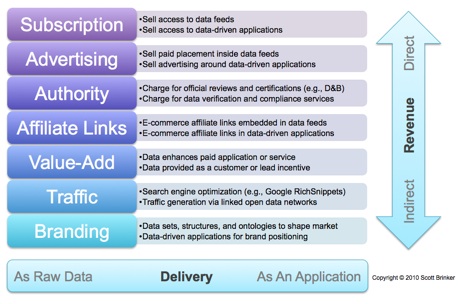
I’ve organized these by how revenue is generated, from direct money-for-data to indirect branding programs.
Within each of these revenue models, there’s also a secondary dimension of how the data is delivered, whether in raw form for others to leverage in their own applications or embedded into a pre-packaged application provided directly to end-users.
1. Subscription model. Some data will be valuable enough that you can charge people a subscription to access it. This model has been around for a while, but it will gain new life as linked data standards make it easier for people to consume and mash-up data in novel applications.
2. Advertising model. Advertising: the second oldest profession. Data-driven applications will have plenty of opportunity for contextual ads and sponsorships. One interesting twist will be advertisers who pay to include information in raw data feeds, data-layer ads if you will.
3. Authority model. If anyone can publish data on the web, how will you know what data is good? That problem will be an opportunity for third-party “authorities” to validate data — or do official reviews and certifications that are published as data — and charge for participation. Compliance services are related to this.
4. Affiliate model. Affiliate marketing programs generate over $6 billion/year in commissions and are a major source of transactions and leads for merchants such as Amazon.com. Embedding affiliate links in data, so that they are activated when surfaced into end-user applications, are a natural extension of this existing model.
5. Value-Add model. Useful data can be bundled with other services to make the overall solution more valuable. For example, think of the benchmarking data now included with Google Analytics. Access to data can also be offered earlier in the sales funnel, as a lead generation incentive.
6. Traffic model. As with Google Rich Snippets, data can be used to boost the visibility and ranking of sites in major and vertical search engines. This is data-enhanced search engine optimization (SEO++) to increase traffic. Nickname: the “data for nothing and links for free” model (apologies to Mark Knopfler).
7. Branding model. As Josh Jones-Dilworth said, “Data shapes conversations and markets.” Data branding can use data — and the vocabularies that define and structure data — to position and promote a company’s worldview and differentiation strategy.
Of course, there will be hybrid models that combine several of these approaches.
Particularly in the early days, most organizations will benefit from experimenting with linked data for traffic, branding, and a little value add. Their own value will be learning as much as anything. As the data web matures, and they become more experienced, they may embrace more direct revenue models.
But don’t underestimate the importance of data branding. When it comes to establishing industry standard vocabularies and ontologies, there is a definite first-mover advantage.
For the entrepreneurs in this space, however, everything is fair game.
Can you think of other models? Are you willing to share?


Brilliant analysis!
I’ve been giving this some thought too (though nowhere near as deeply as you).
How do you turn data into revenue?
Scott Brinker offers this view of pricing for data, answering the question How do you turn data into revenue? It’s organized by how revenue is generated, from direct money-for-data to indirect branding programs. Read more at https://chiefmartec.com/…
Thanks, Dharmesh!
I’d imagine that HubSpot has a number of fascinating opportunities in this area. I’ll be excited to see how your thoughts develop in this direction.
Great post as usual!
Some tweaks/suggestions:
1. Subscription – more granular RESTful “toll booth” variant is available to any Linked Data (a data highway) publisher courtesy of HTTP 402
2. Advertising — Adwords 3.0 will be about demographic specificity and precision for: Advertisers, Ad Networks, and Content Providers
3. Branding — Discourse Discovery & Participation is critical success factor #1 for Brand Development & Maintenance
4. Traffic Model — elegance of HTTP referrer links enables reverse progressive demographic data collation and analysis which is critical to the real-time Web
An addition:
Generic HTTP URIs (LINKs with data specificity benefits) are a solution to the missing Web Identity conundrum; they will enable clear identification of all contributors to any economic value chain. Even better, this in-built identification feature provides a low-cost-high-impact attribution mechanism than incentivizes everyone to expose value by references (LINKs) 🙂
Thanks, Kingsley.
These are great suggestions! (I’m now looking forward to hearing your take on the business of linked data at MIT next week more than ever.)
Scott,
Re last comment: s/than/that. Meant to say:
Even better, this in-built identification feature provides a low-cost-high-impact attribution mechanism *that* incentivizes everyone to expose value via references (LINKs).
Re. next week, I am going to be at MIT in the evening for the Semantic Web Gathering & Student session. The 9am panel on tuesday collides badly with my schedule 🙁
Kingsley
I’d question the viability of the Authority model. On the web authority is more and more being replaced by transparent credibility. Clay Shirky calls this “algorithmic authority” in http://www.shirky.com/weblog/2009/11/a-speculative-post-on-the-idea-of-algorithmic-authority/.
He says:
“As more people come to realize that not only do they look to unsupervised processes for answers to certain questions, but that their friends do as well, those groups will come to treat those resources as authoritative.”
If I write an article on heart transplant and I’m a transplant surgeon at Beth Israel Hospital I don’t need third party certification. If I write a blog about the future of social media, my online presence (tweets, posts, replies) will justify my credibility, and again, there’s no need for third party certification. In the first case my authority is obvious. In the second however, it’s so not obvious that even a professional reviewer has no more (or better access to) information to rely on than anyone else.
I think there’s only a very narrow segment of content providers where this model makes sense. And I bet that those to whom it does will hardly be willing to pay for such a service.
Re. Authority, its no different from what we do everyday, the fundamental question we ask (overtly or covertly) is always this: Who Are You and What are Your Credentials.
Credentials are of themselves subjective and interleaved with social factors.
The Web of Linked Data simply shrinks the Who, What, Where, When into a data de-referencing act combined with contextual reasoning for the “Why”.
On mouse click on a URL is basically what this will come down to etc.. 🙂
Kingsley
Hi, Dan. Great post by Clay Shirky.
At a high-level, it sounds like we all agree: some sources will be authoritative in a particular situation, others won’t. The only question is whether that authority is determined by individuals, by aggregators such as Google (Shirky’s algorithmic authority), or by other domain-specific authorities.
I think individuals are great at making these determinations when they’re dealing with things personally at a small scale. If I’m searching for information about heart transplants, it’s reasonable for me to reach the conclusion that the surgeon from Beth Israel is an authoritative source.
But when the scale of a task increases, and when software is used to process (or at least pre-process) voluminous amounts of data, linked across a wide variety of sources, the individual approach seems like it would break down.
Now, algorithmic authority is great for this — and I’d argue that Google has a bit of the Authority model in their business structure. But not all data will lend itself to PageRank-like determination of authority. And, as Shirky points out, even that’s no guarantee of validity.
I’d simply suggest that there might be other kinds of algorithmic authority — and domain-specific authority, things that are more comparable to certificate authorities that enable SSL transactions over the web — that will prove useful in the linked data era.
Scott,
A great post.
Applications on top of Linked Data delivered may be one of the major revenue generators (you do mention it in the diagram and briefly under Affiliates).
If you look at Linked data as a model on which apps can be built enterprise apps that synch public data with their internal data (web intelligence, for example) may give rise to several business application models as well.
Dorai
Just a quick question: Are you talking about LinkedData.org specifically, or linked data movement as a whole?
on the information management and information discovery side of things… linked-data open up whole new dimensions. SBSGRID for example (one of these new vendors) shows associations and connections within information which had not been visible before…
http://www.sbsgrid.net
There’s some great ideas here, thanks. I’ve sought to expand on this here: http://infonomics.ltd.uk/news/blog/2013/03/01/open-data-business-models/